|
> Verzeichnis der Dokumente mit den theoretischen Grundlagen |
|
Letzte
Bearbeitung dieses Dokuments: |
Voraussetzungen für das Verständnis dieses Dokuments:* Kenntnisse über
relationale Datenbanken. |
Ungefährer Zeitbedarf zum Durcharbeiten dieses Dokuments:Das
ist ein Dokument mit einem Überblick über die
Realisierung von Business-Objects mit Java-Klassen. |
Dieses Dokument beschreibt die Struktur der Klasse, mit der ein Datenbank-Zugriff auf genau eine DB-Tabelle ausgeführt wird.
Im
ersten Teil des Dokumentes werden die Motive des Autors, jeweils
eigene Klassen für den Zugriff auf genau eine Datenbank-Tabelle
zu entwerfen, dargelegt.
Diese Klassen werden als DBA-
(DataBase-Access- / Datenbank-Zugriffs-) Klassen bezeichnet.
Im zweiten Teil des Dokumentes wird dargestellt, wie die Führung der Historie von Änderungen implementiert ist.
Vorbedingungen
Graphische
Darstellung der Struktur einer DBA-Klasse
* Basisklasse
(im JavaScout Fat-Client-Framework)
* DBA-Klasse
für eine bestimmte DB-Tabelle
Welche
Aufgabe hat eine DBA-Klasse – welche Aufgabe hat sie
nicht
* 'Spiegel'
genau einer Datenbank-Tabelle
* Definition
der Attributsnamen der DB-Tabelle als Konstanten (zur
Fehlerminimierung)
* Methoden
für 'insert', 'update', 'delete' und 'select' (mit verschiedenen
Kriterien) auf der DB-Tabelle
* Standardisierte
Methoden zur Übertragung der Werte von der DB-Tabelle in die
Variablen des DBA-Objekts
* Keine
'Integritätsprüfung' der Werte
Attribute
zur Führung der Historie von Änderungen
* Beispiel
aus einem existierenden Programm
* Allgemeine
Attribute (Common Attributes) auf jeder DB-Tabelle
* Vor-
und Nachteile dieser Gestaltung – und: Nein ich kriege keine
Provision von Festplattenherstellern ;-)
Weitere
Schritte und verwandte Dokumentation
Einfache Kenntnisse über den Aufbau und die Kommandos von relationalen Datenbanken.
Einfache Kenntnisse über den Entwurf von Klassen in Java.
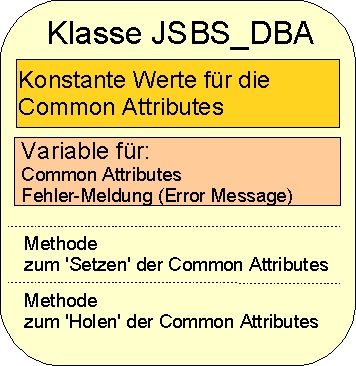
Die folgenden Unterteilungen zeigen vereinfacht, welche Variablen und Methoden in der DBA-Basisklasse und einer abgeleiteten DBA-Klasse implementiert sind.
Für den Java-Code der Basiklasse folgen Sie bitte dem Link zu JSBS_DBA .
In der Basisklasse sind nur Konstante, Variable und Methoden definiert, die die Behandlung der Attribute zur Führung der Historie von Änderungen (Common Attributes) notwendig sind.
Die
Methoden enthalten die Übertragung der Werte der Variablen zu
und von einem (als Parameter übergebenen) Wert vom Java-Typ
'SQLResultSet'.
Über das 'SQLResultSet' werden die Werte
zwischen dem Java-Programm und dem Datenbanksystem übertragen.
Für
jede DB-Tabelle wird eine eigene DBA-Klasse implementiert.
Diese
Klasse erbt die im vorigen Punkt vorgestellte Basisklasse JSBS_DBA.

Die
Konvention für den Namen der Klasse ist folgende:
proj
wird ersetzt durch den Kurznamen des Projektes oder Teilprojektes, zu
dem die Datenbank-Tabelle gehört.
table wird
ersetzt durch den Namen der Datenbank-Tabelle.
Eine Erläuterung der Konstanten, Variablen und Methoden finden Sie im folgenden Punkt.
Die folgenden Unterteilungen zeigen vereinfacht, welche Variablen und Methoden in der DBA-Basisklasse und einer abgeleiteten DBA-Klasse implementiert sind.
Grundsatz-Regel:
Eine
DBA-Klasse gehört zu genau einer DB-Tabelle und greift nur auf
diese zu:
Andere DB-Tabellen sind tabu – es wird auch nicht
von dort gelesen.
Die
Variablen der DBA-Klasse repräsentieren die Attribute der
DB-Tabelle; wenn notwendig wird eine Transformation ausgeführt.
Aus historischen
Entwicklung ist entstanden, dass die Datentypen in Java teilweise
unterschiedlich zu jenen der SQL-Syntax sind oder in SQL nicht
abgebildet sind (z.B. der Typ 'boolean') und in der DBA-Klasse
zwischen SQL-Typ und Java-Typ transformiert werden müssen.
Es wäre eine nicht zu rechtfertigende Einschränkung, nicht das volle Spektrum der Java-Typen zu verwenden – deswegen ist es auch Aufgabe der DBA-Klasse, eine Transformation zwischen Java-Typ und SQL-Typ auszuführen.
Attributs-Namen
der DB-Tabelle und der Name der DB-Tabelle sind als Konstante Werte
definiert.
Grund dafür ist, dass die SQL-Kommandos
Zeichenketten (Java-Typ: String) sind.
Das Schreiben einer extra
Zeichenkette für jede Methode, die ein SQL-Kommando ausführt
ist anfällig für Fehler weil die syntaktische Richtigkeit
der des SQL-Kommandos erst beim Ausführen des SQL-Kommandos
überprüft wird.
Durch das Definieren des Namens der
DB-Tabelle und der Namen der Attribute als Konstante Werte und
Zusammensetzen des SQL-Kommandos aus diesen Konstanten wird
erreicht, dass die Attributs-Namen der DB-Tabelle in den
SQL-Kommandos aller Methoden gleich sind.
Tippfehler werden damit vermieden – bzw. fallen beim ersten ausgeführten SQL-Kommando auf.
DBA-Klassen
führen nur Basis-Operationen auf 'ihre' DB-Tabelle aus.
Diese
Regel wurde eingeführt, um die Aufgaben von DBA- und BO-Klassen
klar zu trennen.
Durch die einfache und standisierte Logik des
Codes in der DBA-Klasse können DBA-Klassen schnell
implementiert werden wenn der Entwurd der Datenbank festgelegt ist.
Mit dem implementieren der Methoden für 'insert',
'update', 'delete', 'selectByDataSetId' und 'selectByuserKnownKey'
ist eine Basisfunktionalität geschaffen, auf die BO-Klassen
aufbauen können.
Mit der genaueren Definition der
Verarbeitungs-Regeln einer BO-Klasse wird es nötig sein,
weitere Methoden für eine 'select' mit Aufgaben-definierten
Kriterien zu implementieren.
Mit einiger Übung ist das
Schreiben des passenden Codes eine Routine-Arbeit.
Die Methoden der DBA-Klasse werden von den Business-Objects verwendet um ihre Daten zu 'sammeln'; komplexe Regeln sind in den BO-Klassen implementiert.
Eigene
Methoden übertragen die Variablen der DBA-Klasse in die Klassen
für den DB-Zugriff – und umgekehrt.
Die Erklärung
mag erst mit tieferer Kenntnis des Codes und nach den ersten selbst
erstellten DBA-Klassen verstanden werden.
Das Einfügen
der Werte in ein SQL-Kommando (Java-Klasse: 'SQLStatement') bzw. das
Auslesen der Ergebnis-Werte nach einem SQL-'Select' (Java-Klasse:
'SQLResultSet') erfolgt mit diesen speziellen Klassen für die
Kommunikation mit dem DB-System.
Dieses Einfügen bzw.
Auslesen der Werte erfolgt bei jedem Zugriff auf die DB-Tabelle;
d.h. bei jeder Methode, die ein SQL-Kommando enthält.
Damit
dies in jeder Methode gleich erfolgt, wird je eine Methode für
das Füllen des 'SQLStatement' bzw. Auslesen der Werte aus dem
'SQLResultSet' implementiert. Diese Methoden werden dann von allen
Methoden vor bzw. nach dem Ausführen des SQL-Kommandos
aufgerufen.
Bei Erweiterungen um neue Attribute müssen damit der Java-Code nur an einer genau definierten Stelle angepaßt werden und nicht mehrere Methoden mit je einem SQL-Kommando.
Nicht
Aufgabe einer DBA-Klasse ist die Prüfung der Integrität
der Daten.
Den 'korrekten Zusammenhang' aller Werte in den
Attributen zu prüfen ist Aufgabe des Business-Objects.
Es
würde die Aufgabe dieses Dokumentes übersteigen, eine
ausführliche Begründung dafür zu geben – ich
hoffe aber, mit einem Beispiel aus der Praxis die Idee für die
Regel zu vermitteln:
Generell ist bei der Bestellung eines
Produktes ein Preis für das Produkt vereinbart.
Bei
Bestellungen von Ersatzteilen kommt es häufig vor, dass der
Einzelhändler den Preis des Produktes (Ersatzteil) noch nicht
kennt.
Der Kunde braucht das Ersatzteil aber 'um jeden Preis',
will nicht erst auf ein Angebot warten - und kann nur darauf
vertrauen, dass das Produkt zu einem fairen Preis in Rechnung
gestellt wird.
Im Warenwirtschaftssystem muss die Regel
gelten, dass ein Produkt ohne bekannten Verkaufspreis existieren
darf – sonst wäre die Erfassung solcher Produkte nicht
möglich und es könnte nicht im Warenwirtschaftssystem
verfolgt werden, ob die Antwort (Preisauskunft) des Zulieferers
'überfällig' ist.
Für solche Produkte darf auch
eine Bestell-Position ohne vereinbarten Verkaufspreis
existieren.
Innerhalb der DBA-Klasse für die
Bestell-Position kann aber nur mit den Daten der Bestell-Position
nicht entschieden werden, ob ein fehlender Verkaufspreis erlaubt
ist, wenn die Daten des 'Produkt' nicht bekannt sind.
In der
DBA-Klasse für die 'Bestell-Position' auf das 'Produkt'
zuzugreifen widerspricht aber der Regel, dass eine DBA-Klasse nur
auf 'ihre' DB-Tabelle zugreift.
Aus
Erfahrung kann ich behaupten, dass eine solche 'Querprüfung' in
der Klasse für das Business-Object leichter zu implementieren
ist.
Die folgenden Unterteilungen zeigen vereinfacht, welche Variablen und Methoden in der DBA-Basisklasse und einer abgeleiteten DBA-Klasse implementiert sind.
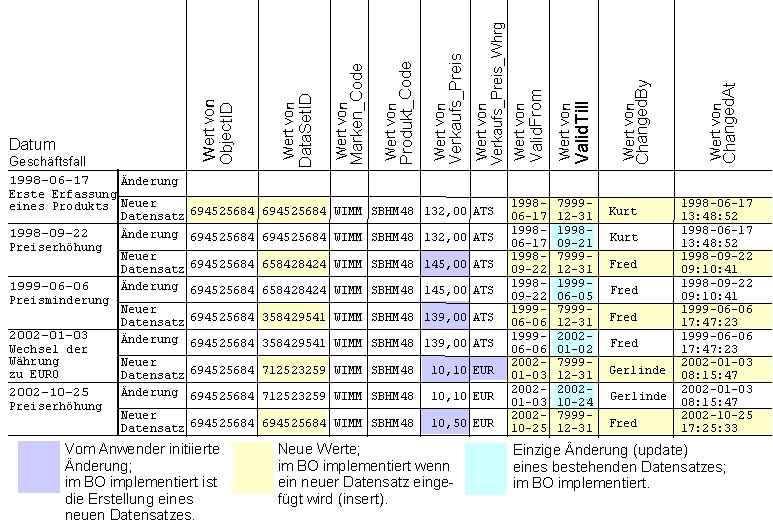
Das Schema verdeutlicht, wie eine Historie von Änderungen aufgezeichnet wird.
Wenn
ein Anwender eine Änderung eines Attributes durchführt,
wird die Gültigkeit des aktuellen Datensatzes beendet und eine
neuer Datensatz auf der Datenbank-Tabelle angelegt.
Dieser neue
Datensatz enthält die aktuell gültigen Werte und
zusätzliche Information, wer wann die Änderung durchgeführt
hat.
Für
das Aufzeichnen des Verursachers und des Zeitpunkts, der eindeutigen
Identifikation eines Datensatzes (Primär-Schlüssel), der
Zusammengehörigkeit der Datensätze eines Daten-Objektes und
der Dauer der Gültigkeit werden 'Allgemeine Attribute' (Common
Attributes) verwendet.
Diese 'Allgemeinen Attribute' sind auf
jeder Datenbank-Tabelle vorhanden und im nächsten Abschnitt
beschrieben.
Mit
Hilfe dieser Attribute wird die 'Historie' der Änderungen auf
der DB-Tabelle geführt.
Für den Java-Code der
Basiklasse, in der die Common Attributes definiert sind, folgen Sie
bitte dem Link zu JSBS_DBA
.
In Klammer ist der SQL-Typ des jeweiligen Attributes
angegeben.
ObjectID
(DOUBLE)
Interner Schlüsselbegriff (Surrogat) eines Objektes
der über die gesamte Lebenszeit (bis zum Erreichen des
Zeitpunktes in 'ValidTill') gleich bleibt.
Dieses Surrogat ist
dem 'Anwender-bekannten' Schlüssel (im obigen Beispiel:
Marken_Code und Produkt_Code) zugeordnet.
Das Surrogat wird
deswegen verwendet, weil durch den Datentyp (DOUBLE) eine Referenz
auf diesen Datensatz weniger Platz beansprucht als ein
möblicherweise langer 'Anwender-bekannter' Schlüssel.
Technisch
ist der Wert von ObjectID jener Wert, den DataSetID hatte als das
Objekt erstmals in der Datenbank-Tabelle angelegt wurde.
ClientID
(INTEGER)
Vorkehrung für die Erstellung von
Mandanten-fähigen Anwendungsprogrammen.
Dabei kann ein
Anwendungsprogramm beliebig viele rechtlich voneinander unabhängige
Unternehmen (einzelne 'Mandanten') bedienen.
Im
Anwendungsprogramm muss sicher gestellt werden, dass Mitarbeiter
eines Unternehmens nicht auf Daten der anderen Unternehmen zugreifen
können.
In den Code-Mustern des JavaScout
Fat-Client-Frameworks (JS-FCF) wird der Wert für
den Mandant im Attribut intClientID
der Basisklasse JSBS_UniversalParameters
gehalten.
Als Initialwert ist '0' festgelegt.
Wird ein
Anwendungsprogramm als Mandanten-fähig erstellt ist es Aufgabe
des Anwendungsprogramms, bei der Anmeldung eines Benutzers den
Mandanten, zu dem dieser Benutzer gehört, zu ermitteln und den
Wert im Attribut intClientID
der Basisklasse JSBS_UniversalParameters
zu speichern.
In den Code-Mustern für die Business-Objects
und DBA-(DataBase-Access-) Objekte (Verzeichnis unter Vorstellung
des JavaScout Fat-Client-Frameworks (JS-FCF) > Theoretische
Grundlagen der Datenspeicherung mit Business-Objects
(Geschäfts-Objekten) und Muster-Code) wird der Wert
aus dem Attribut in die jeweiligen SQL-Kommandos übertragen.
DataSetID
(DOUBLE)
Primärer Schlüssel des Datensatzes; eindeutige
Identifizierung des Datensatzes innerhalb der DB-Tabelle.
Der
Wert ist eine Zufallszahl weil die meisten Datanbank-Systeme auf
einen weit gestreuten Wertebereich des Primärschlüssels
mit einer kürzeren Abfragezeit reagieren.
CreatedBy
(VARCHAR(254))
Name des Benutzers der das Objekt (der erste
Datensatz mit einem 'Anwender-bekannten' Schlüssel) in die
DB-Tabelle eingefügt hat.
CreatedAt
(TIMESTAMP)
Datum und Uhrzeit, wann das Objekt in die DB-Tabelle
eingefügt wurde.
ChangedBy
(VARCHAR(254))
Name des Benutzers der das Objekt auf die jetzt
enthaltenen Werte geändert hat.
Dieser Benutzer hat diesen
Datensatz (eindeutig identifiziert mit dem 'DataSetID') in die
DB-Tabelle eingefügt.
ChangedAt
(TIMESTAMP)
Datum und Uhrzeit, wann dieser Datensatz in die
DB-Tabelle eingefügt wurde.
ValidFrom
(DATE)
Datum ab wann die Werte in diesem Datensatz gültig
sind.
Die Gültigkeit beginnt um 0:00 Uhr des angegebenen
Datums.
ValidTill
(DATE)
Datum bis wann die Werte in diesem Datensatz gültig
sind.
Die Gültigkeit endet um 24:00 Uhr des angegebenen
Datums.
Nach 8 Jahren des Einsatzes eine Warenwirtschaftssystems mit ca. 1500 Kunden, ca. 4000 Produkten und ca. 500 Bestell-Positionen pro Woche zeigt sich, dass mögliche Ängste über ein 'Explodieren' des Bedarfs an Speicherplatz nicht wahr wurden.
Zuerst zu den Vorteilen dieser Art der Führung einer Historie:
Die
'History' der Veränderung von Daten ist leicht zu führen.
Jede
Datenbank-Tabelle beherbergt die Geschichte der Veränderung auf
ihren Daten – eine eigene Tabelle oder Datei mit Log-Daten ist
nicht notwendig.
Durch leicht zu definierende 'Commit'-Punkte ist
die Konsistenz der Daten gewährleistet. Eine Konsistenz der
Daten wäre bei einer getrennten Log-Datei schwerer zu
erreichen.
Die
'History' kann leicht gelesen werden.
Die
Geschichte der Veränderung eines bestimmten 'Objektes' (z.B.
einer Rechnungsadresse) kann leicht durch passende
'select'-Kommandos gelesen werden.
Ökononomische
Gründe.
Die
Einführung dieser Art der 'Historie' war einfach, ist
standardisiert und damit gleichbleibend für jedes
DBA.
Gemeinsam mit den fallenden Preisen für Festplatten
(bzw. der rasanten Kapazitätssteigerung bei leicht fallenden
Preisen) sind keine zusätzlichen Kosten angefallen.
Die
eingesparte Zeit (gegenüber der Entwicklung eines eigenen
Log-Systems) konnte ich für die Arbeit in anderen Projekten
nutzen.
Einziger Nachteil:
Der
Speicherplatzbedarf ist höher als mit einer Log-Datei.
Ja,
das stimmt.
Dieser Nachteil wird aber ökonomisch durch die
Vorteile mehr als kompensiert.
Nein
– ich bekommen keine Provision von Festplattenherstellern
-
oder die Erfahrungen nach 8 Jahren Betrieb:
Der
Speicherplatzbedarf ist nicht 'explodiert'.
In
den ersten Wochen nach der Einführung ist die Datenbank stark
gewachsen.
Das war aber durch das Anlegen von Kunden und
Produkten bedingt.
So ist die Anzahl täglich gewachsen und
es wurden auch häufig Eingabefehler ausgebessert.
Stammdaten
machen nur ca. 20 % der Datenmenge aus.
Stammdaten
(für Rechnungs- und Lieferadressen, Produkte, etc.) machen nur
ca. 20 % des Datenvolumens aus.
Diese werden weniger oft geändert
als ich angenommen habe. Der größte Teil dieser
Änderungen ist das Ändern von Preisen für Produkte.
Andere Daten werden nur sehr selten geändert weil die
Stammdaten für Kunden und Produkte jetzt fast fehlerfrei
sind.
Die Produkte sind keine Saisonwaren und das Produkt-Angebot
wechselt nicht stark.
Kunden ändern selten Ihren Standort
oder sonstige Daten – vielleicht einmal die Nummer des
Mobil-Telefons.
Bewegungsdaten
werden kaum geändert.
Bewegungsdaten
(Bestellungen, Lieferscheine, Rechnungen) machen den größten
Teil der Daten aus – werden aber nur selten geändert.
Das
Datenvolumen, das durch die durchschnittlich 100 Bestellpositionen
pro Tag erzeugt wird ist gut kalkulierbar und relativ gering.
Diese
Daten werden nur in seltenen Fällen nach dem Erfassen geändert;
hauptsächlich nur wenn ein Sonderpreis für den Kunden
nachträglich erfaßt werden muß.
Begründete
Ausnahmen werden zugelassen.
In
Ausnahmefällen wird auf das Führen der 'History'
verzichtet.
Ein solcher Fall ist, wenn das Nachverfolgen von
Änderungen unwichtig ist.
Zum Beispiel: wird beim Schließen
eines Fensters die Position und die Größe eines Fensters
für den Anwender auf der Datenbank gespeichert damit beim
neuerlichen Öffnen des Fensters die eingestellte Größe
und Position wieder hergestellt werden kann. Eine solche Information
(wie sah das Fenster für die Bearbeitung einer Rechnungsadresse
für Anwender 'Fred' am 13. April 1999 aus ?) ist wertlos.
Ein
zweiter Fall ist, wenn die Gestaltung einer Datenbank-Tabelle
bereits die zeitliche Veränderung von Daten berücksichtigt.
Zum
Beispiel ist beim 'Produkt-Lagerstand' nicht nur die aktuelle Menge
gespeichert, sondern auch, welche Menge für welche Bestellung
entnommen wurde.
Damit wird schon eine Historie über die
Veränderung der Daten geführt.
|
Dokument |
Inhalt |
|
Liste der Dokumente mit detaillierten Beschreibungen. |